Deterministic Quoting: Making LLMs Safer for Healthcare
LLMs have the potential to revolutionise our field of healthcare, but the fear and reality of hallucinations prevent adoption in most applications.
At Invetech, we’re working on “Deterministic Quoting”, a new technique that ensures quotations from source material are verbatim, not hallucinated.

In this example, everything displayed with a blue background is guaranteed to be verbatim from source material. No hallucinations. LLMs remain imperfect, so it may still choose to quote the wrong part of the source material, but only “real” quotations are displayed on blue - they are deterministically generated.
We think Deterministic Quoting is an “enabler” for deploying LLMs where there are serious consequences to incorrect information, such as:
- AIs that process medical records
- AIs that assist in diagnosis
- AIs which reference medical guidelines
Many LLM systems can be designed to deterministically quote. This article provides motivation and explains a basic implementation.
Contents:
- Hallucinations Matter
- Introducing Deterministic Quoting
- How Well Does It Work?
- Applications
- Technical Details: How is it Implemented?
- Beyond the Minimalist Implementation
- Conclusion: Is This Really Ready For Healthcare?
1. Hallucinations Matter
Hallucinations are endemic to LLM systems.
- The biggest models from OpenAI, Google, Anthropic etc. hallucinate more than 20% of the time in some use-cases
- It’s safe to assume that the next generation (ChatGPT “5”, Gemini 1.5 Ultra, etc.) will continue to hallucinate, albeit at a lower rate
- Some LLMs are trained/prompted to cite sources… but these citations themselves can be hallucinated! This can be particularly problematic: users are more likely to trust authoritative-looking citations
- “Check your own answer” iterative methods can reduce the rate of hallucinations, but only partially.
- Attaching relevant source material to the query (RAG) is better than training/fine-tuning/LoRA (see catastrophic forgetting), but even still the material is sometimes transformed when quoted in the output.
In short: any information that passes through an LLM is potentially “tainted”.
So what?
In naturally conservative fields like healthcare we do not deploy systems that are reliable “most of the time”. Even a low rate of hallucination is enough to prevent adoption at scale for most of our use-cases. We simply can’t burden users with the task of independent verification – mistakes and their consequences are inevitable.
Eventually, LLM quality may be high enough to be trustworthy as-is, but this is not currently within sight. Until then…
2. Introducing: Deterministic Quoting
Deterministic Quoting techniques bridge the LLM “trust gap”.
Applications with Deterministic Quoting provide verbatim “ground-truth” information interspersed with LLM commentary. It combines the convenience and flexibility of the LLM with trustworthy data that is guaranteed to be hallucination-free. Users benefit from the framing and commentary but can easily verify the underlying assumptions without extra action.

The “hallucination-free” guarantee is achieved by ensuring that the data displayed on the blue background has never passed through an LLM (or any non-deterministic AI model). The AI chooses which section of source material to quote, but the retrieval of that text is a traditional non-AI database lookup. That’s the only way to guarantee that an LLM has not transformed text: don’t send it through the LLM in the first place.
The approach is imperfect: the surrounding text (white background) has come directly from an LLM and therefore may still be hallucinated. Or, the AI can choose an irrelevant (but still verbatim) quote to display. Still, the result is a significant improvement: users report intuitively grasping the difference between trusted quotations and prose generated by the LLM.
3. How well does it work?
In practice, we meet the stated goal of “zero false positives” for any quoted text. That is, 100% of all text displayed in the special quote box (the blue background in the examples) is indeed verbatim, not hallucinated.
In addition, several other metrics are useful:
- Are there hallucinations in the non-DQ prose? (ie. white background)
- Was the right quote/data chosen by the LLM? Is it relevant to the question?
- Is user’s query answered?
Here, the underlying LLM remains the limiting factor for quality, DQ is only part of the story. We don’t expect DQ to improve these metrics, our goal is to avoid regressions.
Here are some preliminary results comparing a standard RAG pipeline (Llamaindex + ChatGPT 4) with a modified version with a minimalistic implementation of DQ. N=60, non-public dataset.
| Baseline | Goal | With DQ | |
| Hallucinations in blue box: | N/A | 0 | 0 |
| Hallucinations outside blue box: | 12% | Better than baseline | 2% |
| Was the quote/data relevant? | 90% | Baseline | 92% |
| Is the user’s query answered? | 83% | Baseline | 88% |
While preliminary, this data is consistent with other experiments we have run: adding DQ does not appear to degrade the overall quality of answers. If anything, answer quality may slightly improve.
4. Applications
DQ techniques provide benefit wherever hallucinations are problematic – typically Information Retrieval (eg RAG) and related systems.
- a pharmacist discussing drug interactions and side effects with an AI assistant
- an anxious patient doesn’t get through all of their questions in the 7 minutes they have with their surgeon but has all the time in the world to discuss with a knowledgable AI assistant
- a doctor asks the medical records system if a patient has a history of heart conditions - it responds with a summarised list
- an assistant to front-line medical staff with knowledge of best-practice diagnosis and treatment for common conditions
- an educational aid that allows students to query textbooks or other study material
Proof-of-concept demonstations already exist - organisations are clearly excited about the potential for these systems. But in most of these, there are serious consequences to hallucinations. Few are currently reliable enough to deploy at scale.
Of course, DQ may be applied outside healthcare too - eg. systems with knowledge of legisliation, financial regulation or works of literature. But here, we constrain the discussion to healthcare.
5. Technical Details: How is it Implemented?
While implementations will vary, DQ fundamentally involves a sending LLM outputs to a separate module that replaces potentially-hallucinated quotations with verbatim copies direct from the source material. This replacement is a traditional non-AI database query, that is, it’s “deterministic”.
Before discussing advanced implementations, let’s build a proof-of-concept. The simplest way is to take a typical RAG pipeline and make some modifications.
A “Minimalist Implementation” of DQ: a modified RAG Pipeline
A typical RAG pipeline:
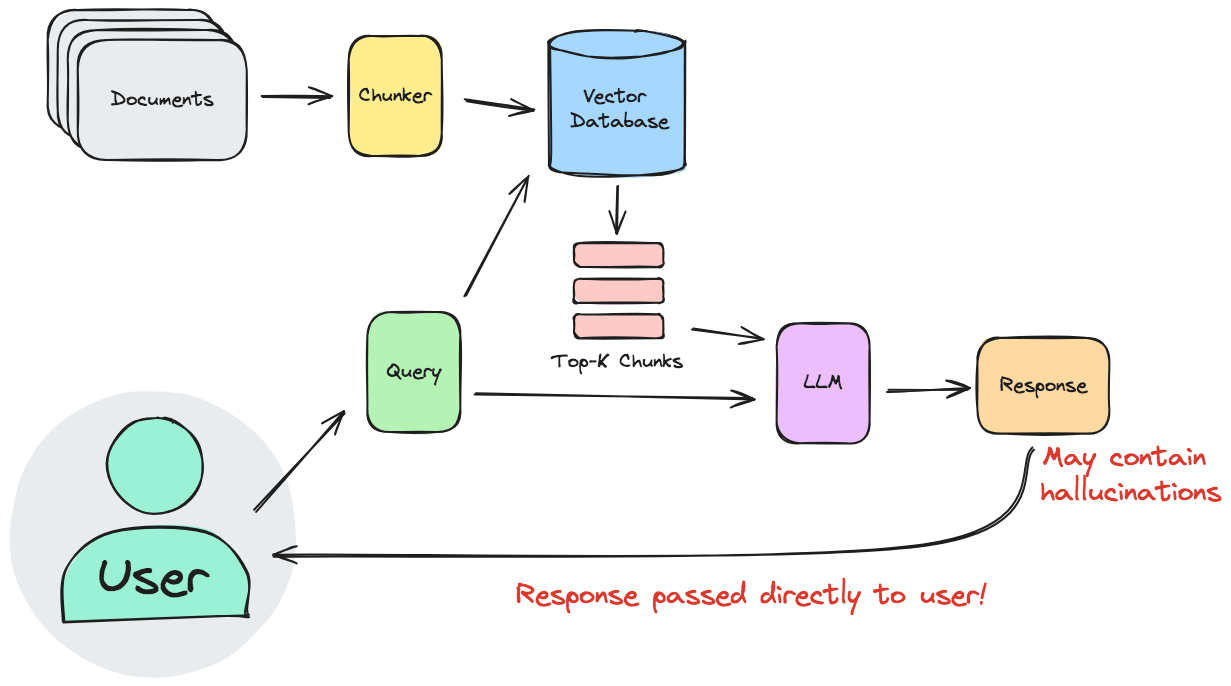
Note how the retrieved source material passes through the LLM - and is therefore liable to be transformed (hallucinated) before it is shown to the user.
We want to fix this by adding a “deterministic lookup” of quotes after all calls to the LLM are complete. Note how the new modules are added after the LLM.
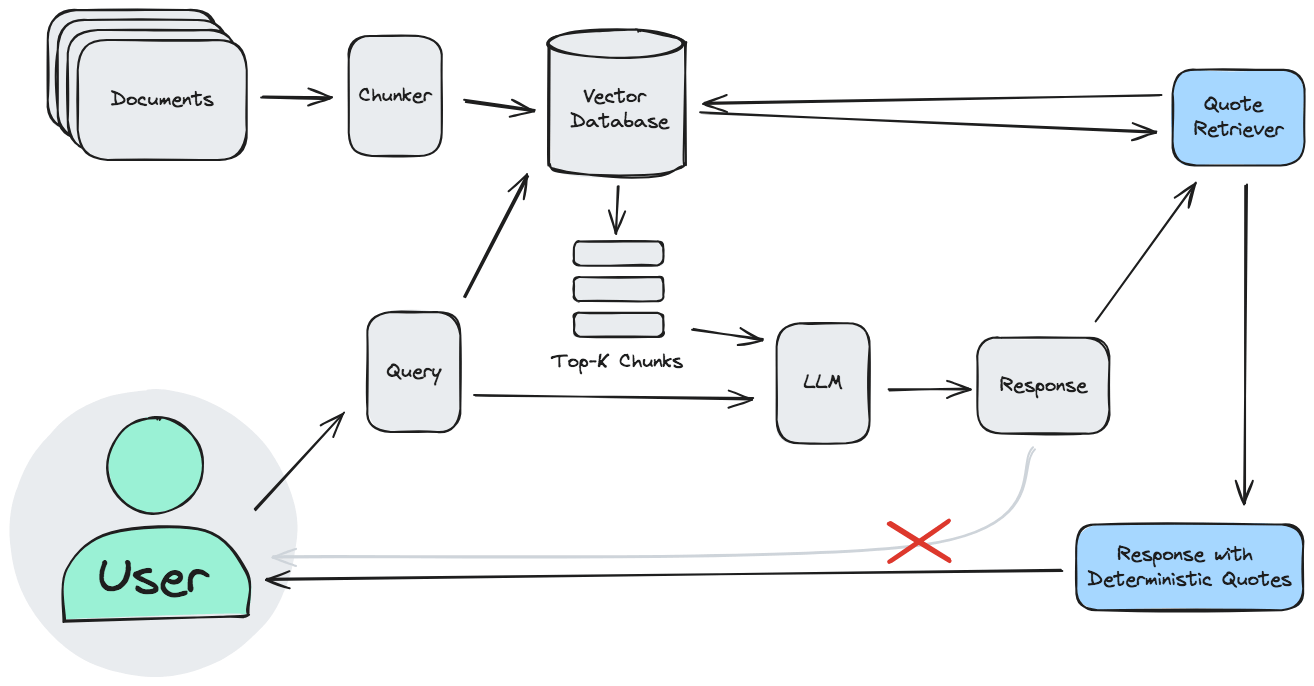
To achieve this, we make six changes to the original:
- Chunker: modify to suit in-line quotation
- Generate a unique reference string for each chunk
- Retrieval: wrap chunks in a structured format - including a unique reference - before passing to the LLM.
- Prompt: instruct the LLM to cite references for all claims and output a structured format for these references
- Deterministic lookup: use those references to loop back to the source material to find the original quote
- Add support to GUI
Chunking Approach
We add two constraints to the document “chunker” - the module that splits our dataset up into indexable pieces.
First, we prefer smaller chunks that are easily displayed in and around the LLM’s commentary. In RAG with current-generation LLMs, chunks are often quite large - a page of text or more. But this simple implementation of DQ only displays whole chunks, not parts. A whole page for each quote would often be too much for users to conveniently parse, so paragraph-sized are preferred. Of course, the LLM can still quote several consecutive paragraphs where relevant.

Second, we want chunk boundaries to be logical to a user: displaying cut-off pieces of a section could be confusing. Such “semantic chunking” can be tedious, depending heavily on the source material structure and format. However, it does seem to provide an improvement in the quality of some answers, presumably because there is semantic value in the structure of the document.
Like most ML systems, source data preparation and chunking are often the most time consuming to implement.
Give Each Chunk a Unique Reference String
We create a unique reference string for each chunk. This string is used in several ways:
- stored in the datastore as metadata for each chunk
- passed into the LLM context as a “header” for its chunk inside a <title> tag
- output by the LLM alongside anything it wants to quote – again in a <title> tag
- (ideally, if meaningful to humans) displayed in the “blue box” as a link to the original source.
This is not always straightforward. Difficulties include:
- unstructured documents. Humans would say “half-way down page 32”
- dealing with duplicates: eg “Section 1: Introduction” may appear in multiple documents, 2 documents may have the same name, or the corpus may contain multiple revisions of the same document
- the stretch goal of making the string meaningful to humans can be difficult, depending on the document set
Prompt Engineering
Here is an example system prompt for a system with access to our internal medical device design standards:
System prompt:
You are an expert Q&A system with excellent knowledge of the internal documentation of our company, Invetech.
Invetech designs medical devices, so it is critical that you always accurately quote the reference information you use to answer the query.
Like typical RAG systems, we instruct the LLM to only answer from the source material, not its learned “memory”. Unlike many RAG systems, however, we instruct the LLM to always cite sources, keeping “commentary” separate from the quotes.
Always answer the query using the provided reference information, and not prior knowledge.
The reference information is provided below as a list of "sections". Each section is encapsulated by a <quote> tag.
Each <quote> contains a <title> tag at the very beginning. Use this title when quoting.
Some rules to follow:
1. Always use the appropriate <quote>s to answer the question.
2. Include a plain English summary in answer to the query, based on the text in the relevant <quote>s. There is no need to simply repeat the quoted text, however.
When citing, we instruct the LLM to start with the unique reference string in a structured format. XML-style works well, but so do json or others.
3. Quote the whole section so the user can see where the information has come from. Always include the <quote> tags, including the title, when quoting.
4. Always start quotes with "<quote>" and end quotes with "</quote>"
5. Quote multiple sections if relevant, but always quote whole sections using the correct format.
6. Use the term "Reference information" instead of "context information"
7. Always quote whole sections verbatim, not a subset.
Retrieval of Top-K Chunks
The only change to retrieval is the format used when inserting into LLM context. We use the same format we want the LLM to output – including the unique reference string from above inside <title> tags. This provides the LLM with examples of the preferred format without eating up valuable context space. An example:
<quote>
<title>ICD-10 Version:2019 - Chapter VI Diseases of the nervous system - G43.1</title>
G43.1 Migraine with aura [classical migraine]
<link>https://icd.who.int/browse10/2019/en#G43.1</link>
</quote>
Deterministic Lookup
After the LLM output has been returned, quotations matching the above format are extracted. In the minimal implementation of DQ, only the unique reference string is kept. The actual quote text is discarded because it may contain hallucinations.
The application looks up the unique reference string in the chunk index. If it matches, the true quotation text is inserted into the <quote> tag text. Otherwise, the unique reference string has been hallucinated – the quotation is invalid.
When this step is complete, everything contained within a <quote> tag is guaranteed to be a valid quotation directly from the source material.
GUI Changes
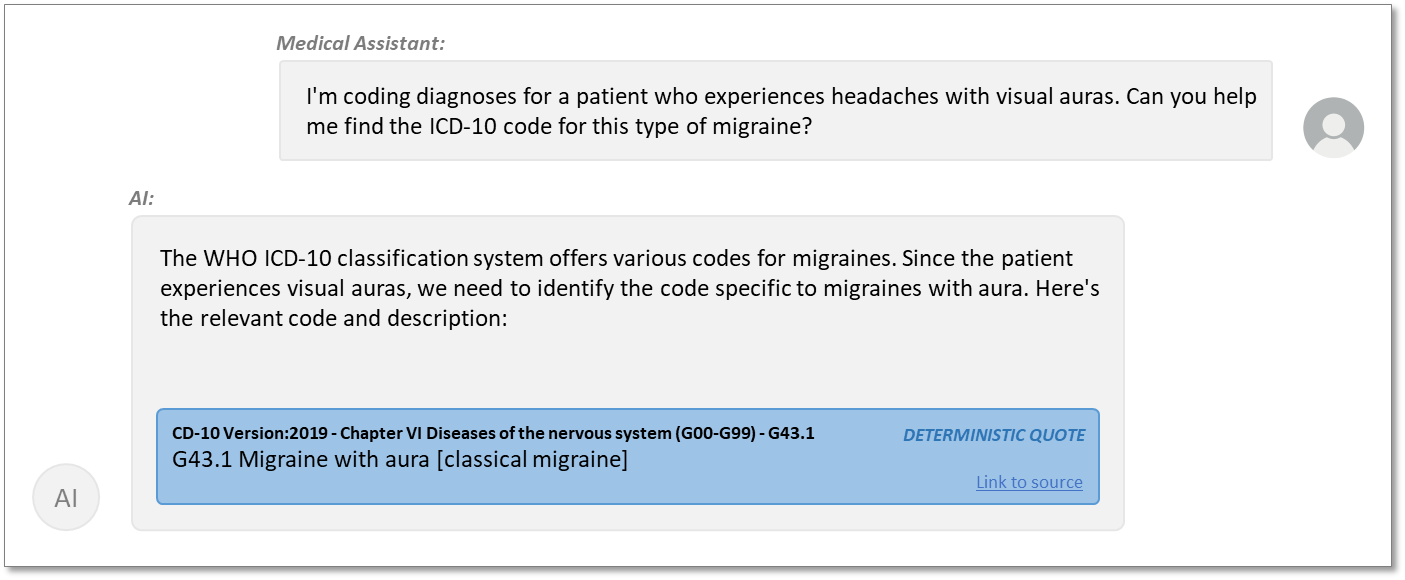
To complete our minimalist implementation of DQ, we modify the GUI to clearly distinguish between quotations and LLM prose. In the examples above, we:
- put the text in a blue box
- add a user-readable reference (ideally the unique reference string)
- label it as deterministically generated
- add a link to the source
6. Beyond the Minimalist Implementation
While the implementation above is a useful explainer there are many opportunities for improvement. Our tests have shown significant improvement beyond the proof-of-principle implementation:
Reducing the rate of irrelevant answers and omissions
- Detect & reject answers that fail to use deterministic quoting
- Detect if the answer fails to answer the question (imperfect, because an LLM is used to do this)
- Replace the “unique reference string matching” with a more sophisticated method of matching a selected quote to the ground-truth database. For example: matching on substring similarity or using constrained generation / extractive QA
- Prompt engineering to encourage “I don’t know” responses
Presenting information the LLMs in a more machine-understandable manner
- Improved versions of semantic chunking - eg overlapping chunks or processing documents multiple times with different chunk sizes
- Adding more meta-data to chunks - For example, sometimes nearby subheading will provide important context
- Diagrams, charts and tables are notoriously difficult for AI systems to understand. DQ has its own challenges with these, though they are much easier to solve than the general problem faced by all RAG systems
- Iterative calls to the LLM to narrow down source material
- Customising parsing and chunking to the dataset, or, where possible, changing dataset format to suit the LLM
Generally, these techniques are not spcific to DQ, but often provide more benefit when used with DQ.
Non-RAG Applications
DQ isn’t limited to RAG systems. However, implementation can be more cumbersome because some parts of the RAG pipeline (eg chunking) are required for DQ.
For example, upcoming models from Google et al. can fit whole books in context - enough to make RAG unnecessary for small corpuses. They still hallucinate, so Deterministic Quoting remains beneficial, but the source data must be chunked (ideally semantically) and indexed as it was in RAG.
7. Conclusion: Is this Really Ready for Healthcare?
Deterministic Quoting helps to bridge the LLM “trust gap”. Combining the flexibility of LLMs with the reliability of non-AI quote lookups, DQ gives users confidence in the “ground truth” data assumed by the AI.
Advanced versions of the technique are still under development, but even basic implementations show significant improvement over the current state-of-the-art. Future versions can provide further improvements to quality of answers and flexibility when parsing a wide range of input documentation.
For some applications, a basic DQ implementation may be the difference between a proof-of-concept and a system with enough trustworthiness to deploy into production. For others, there is still work to be done before we can demonstrate sufficient safety. In all cases, it is clear that some variation of DQ will remain useful as long as models continue to hallucinate.
This article was discussed on Hacker News and linked to by the excellent Simon Willison’s Weblog
Contributors: Chris Herring, Lars Katzfey & I. We work at Invetech
Contact: matthew.yeung@invetech.com.au or LinkedIn